Vision-language models (VLMs) excel in zero-shot
recognition but their performance varies greatly across
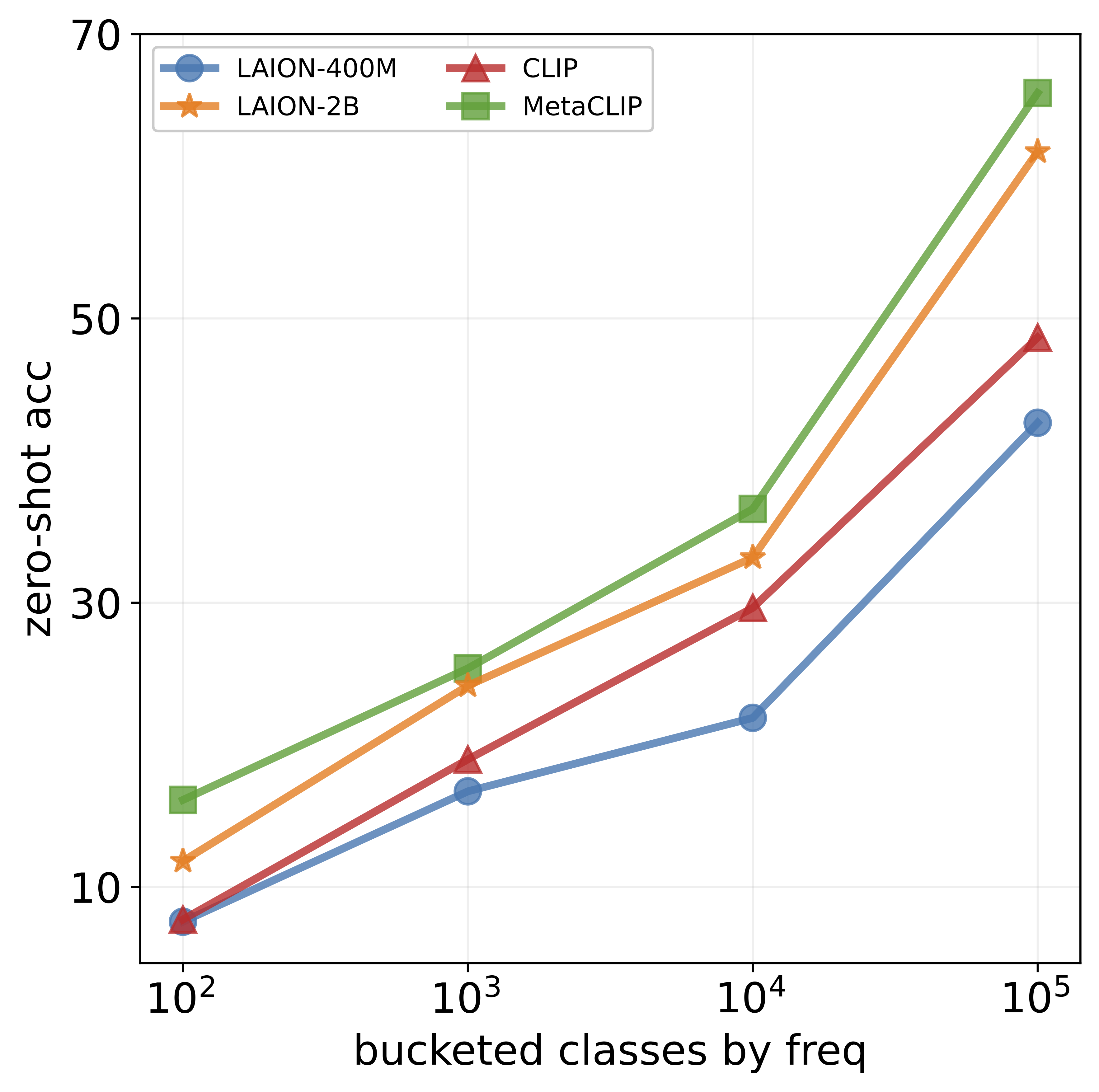
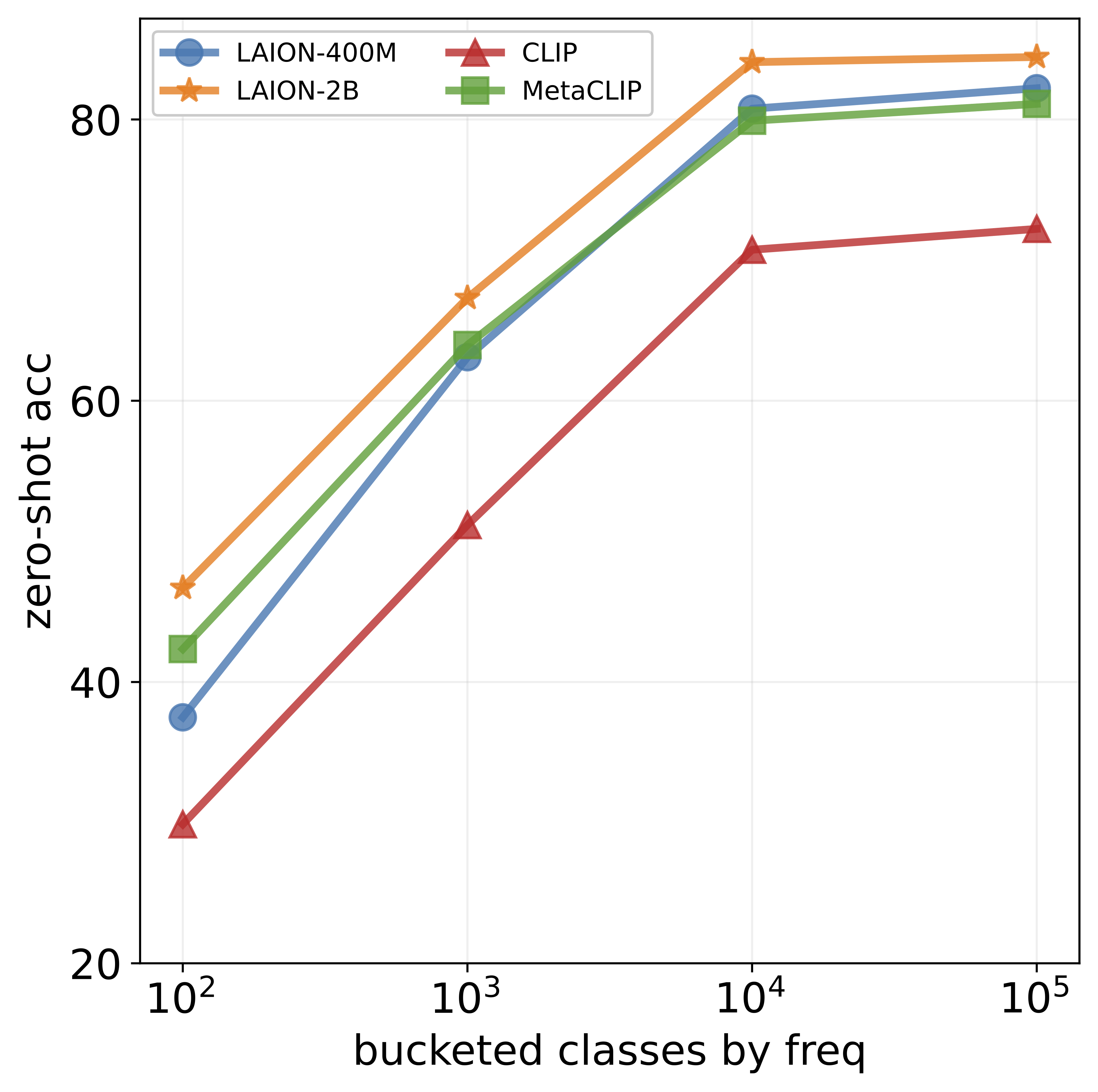
different visual concepts. For example, although CLIP
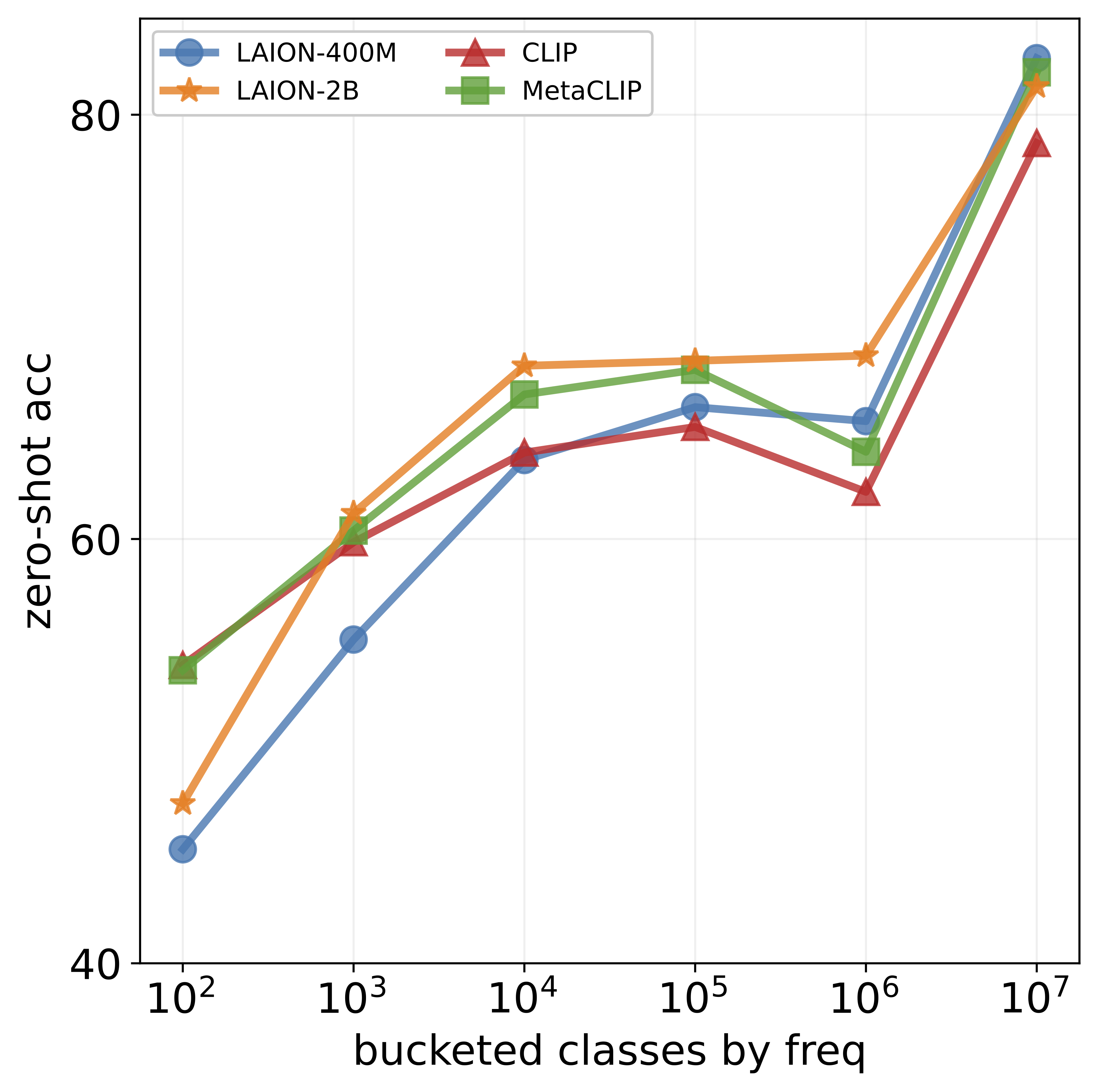
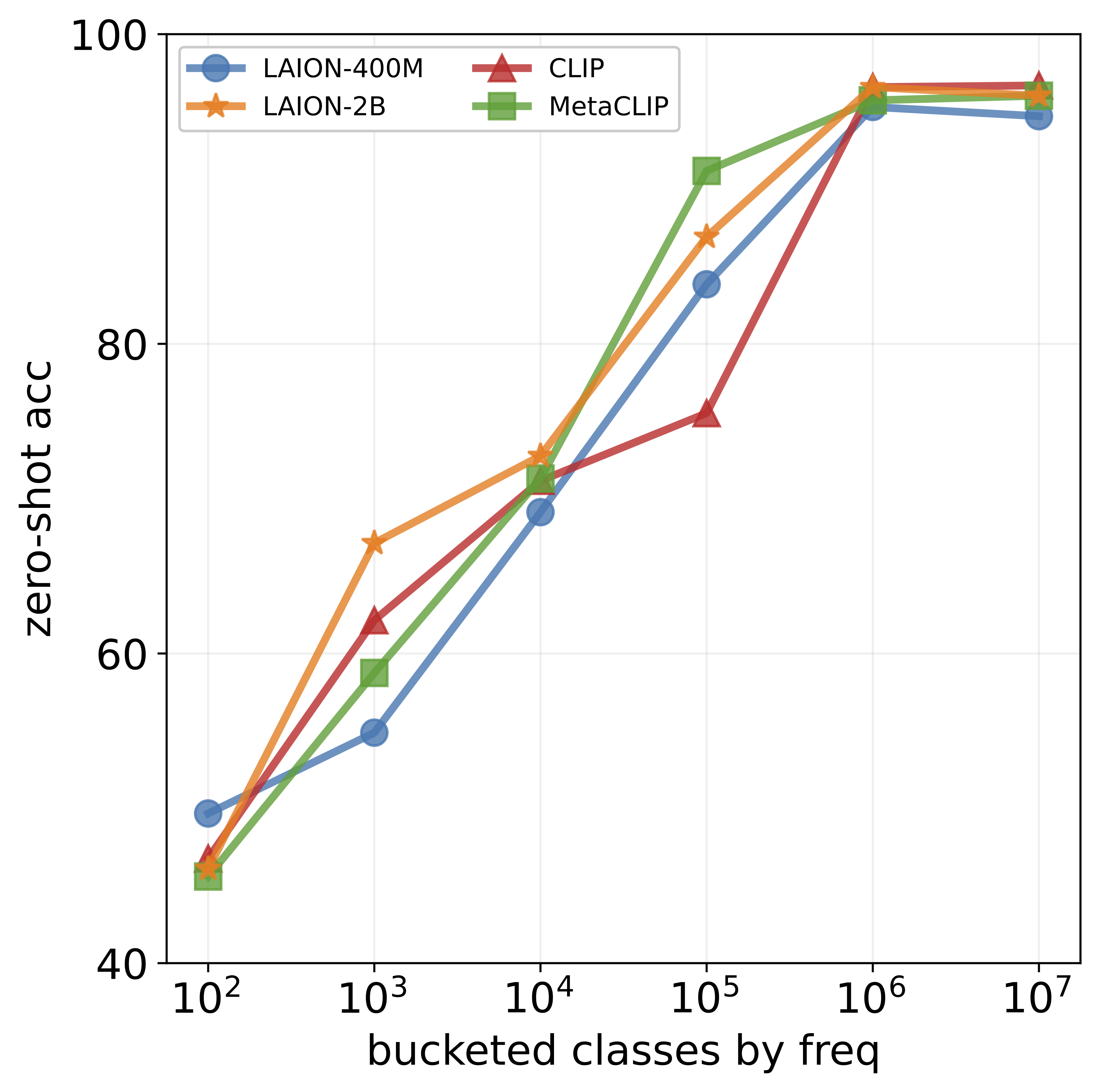
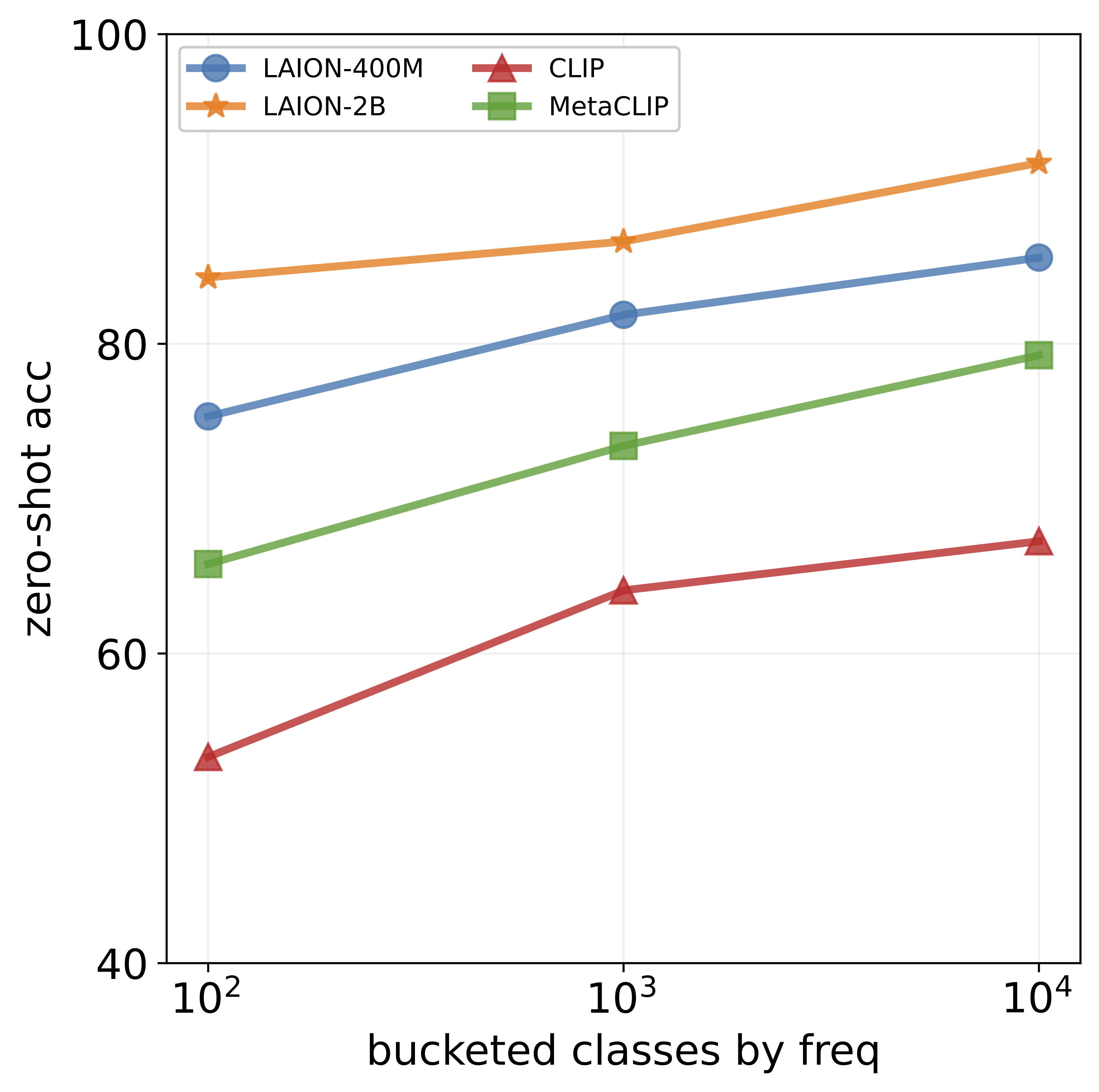
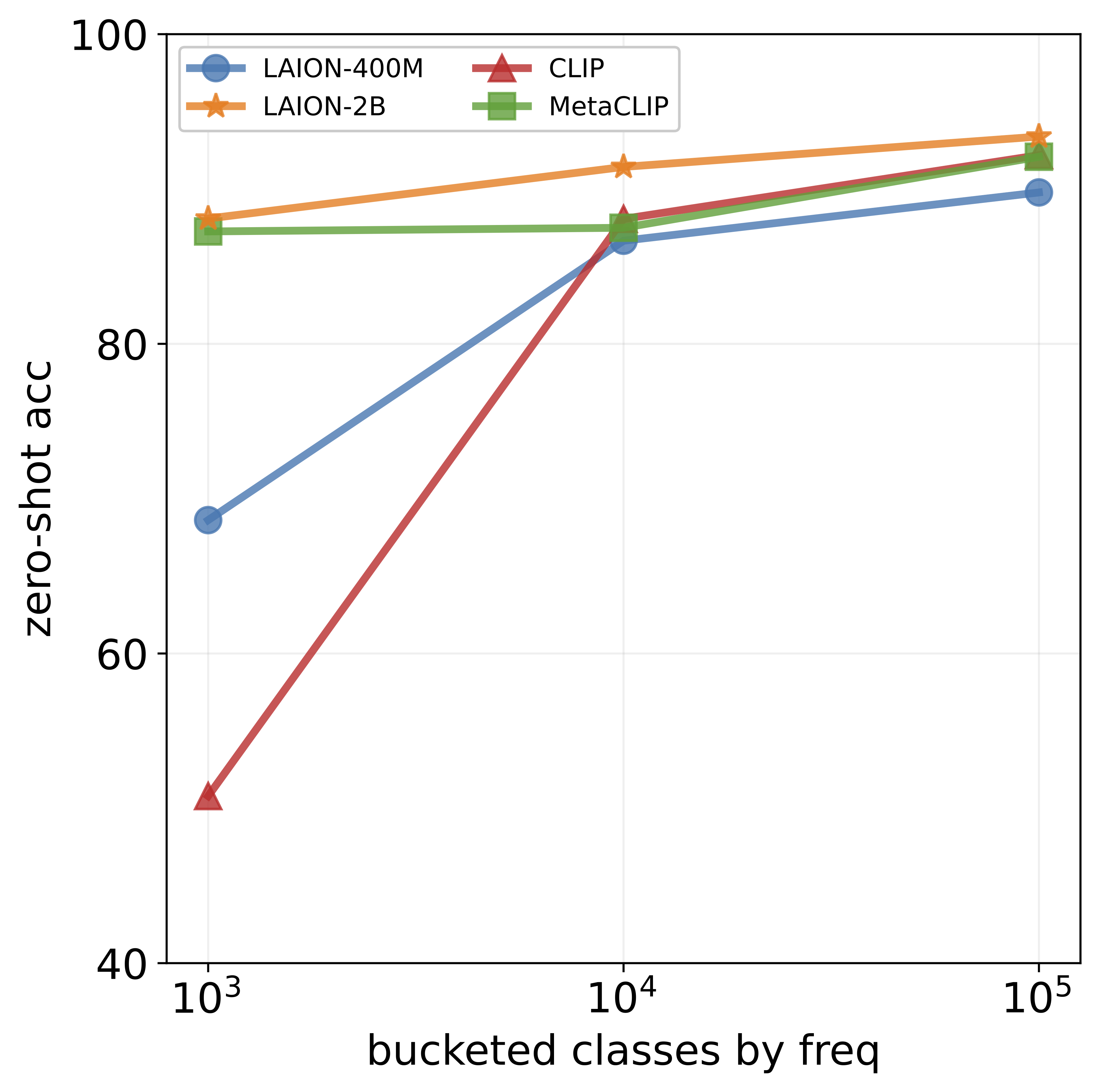
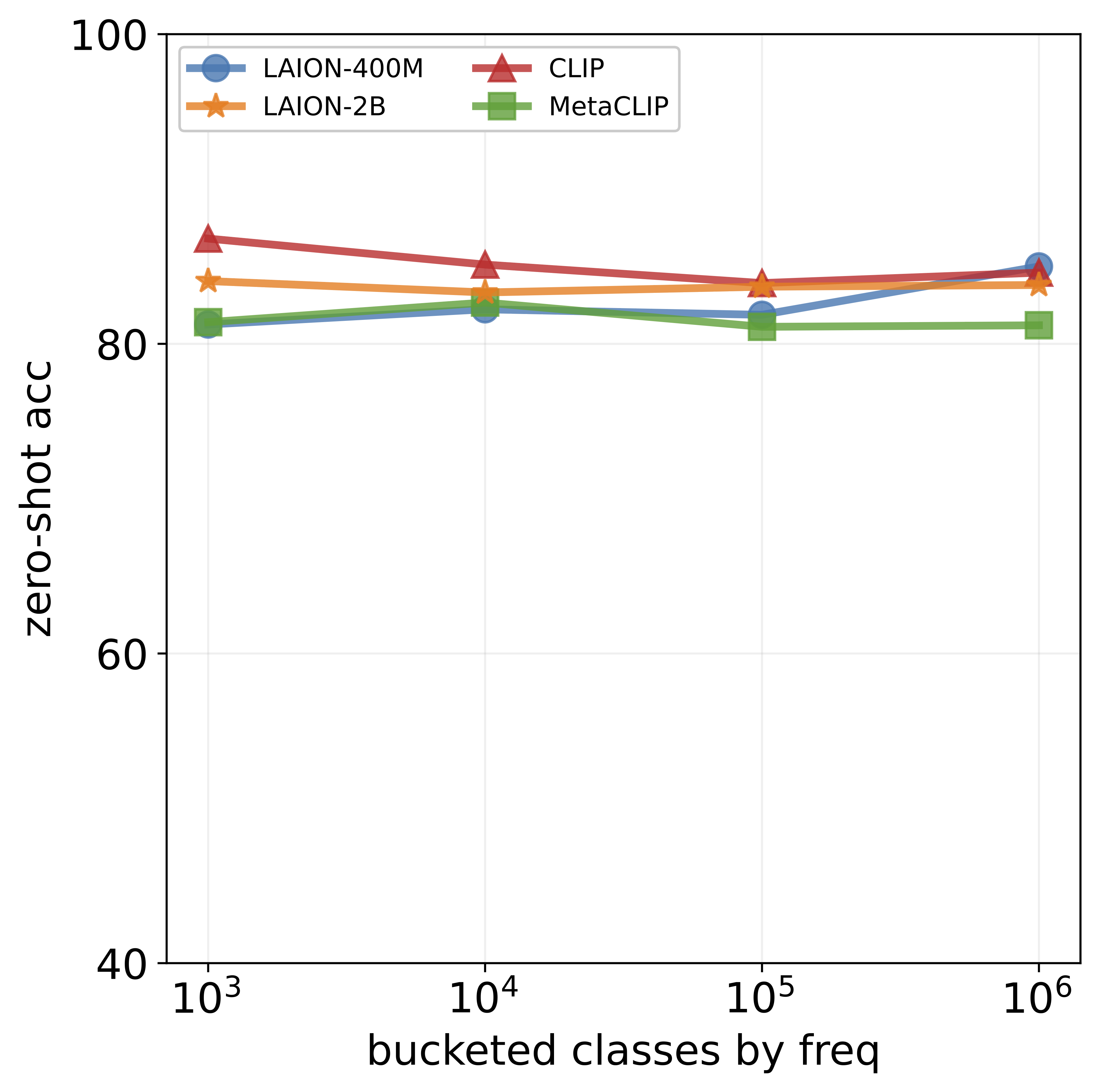
achieves impressive accuracy on ImageNet (60-80%), its
performance drops below 10% for more than ten concepts
like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs’ large-scale datasets is challenging. We address this by using large language models
(LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms
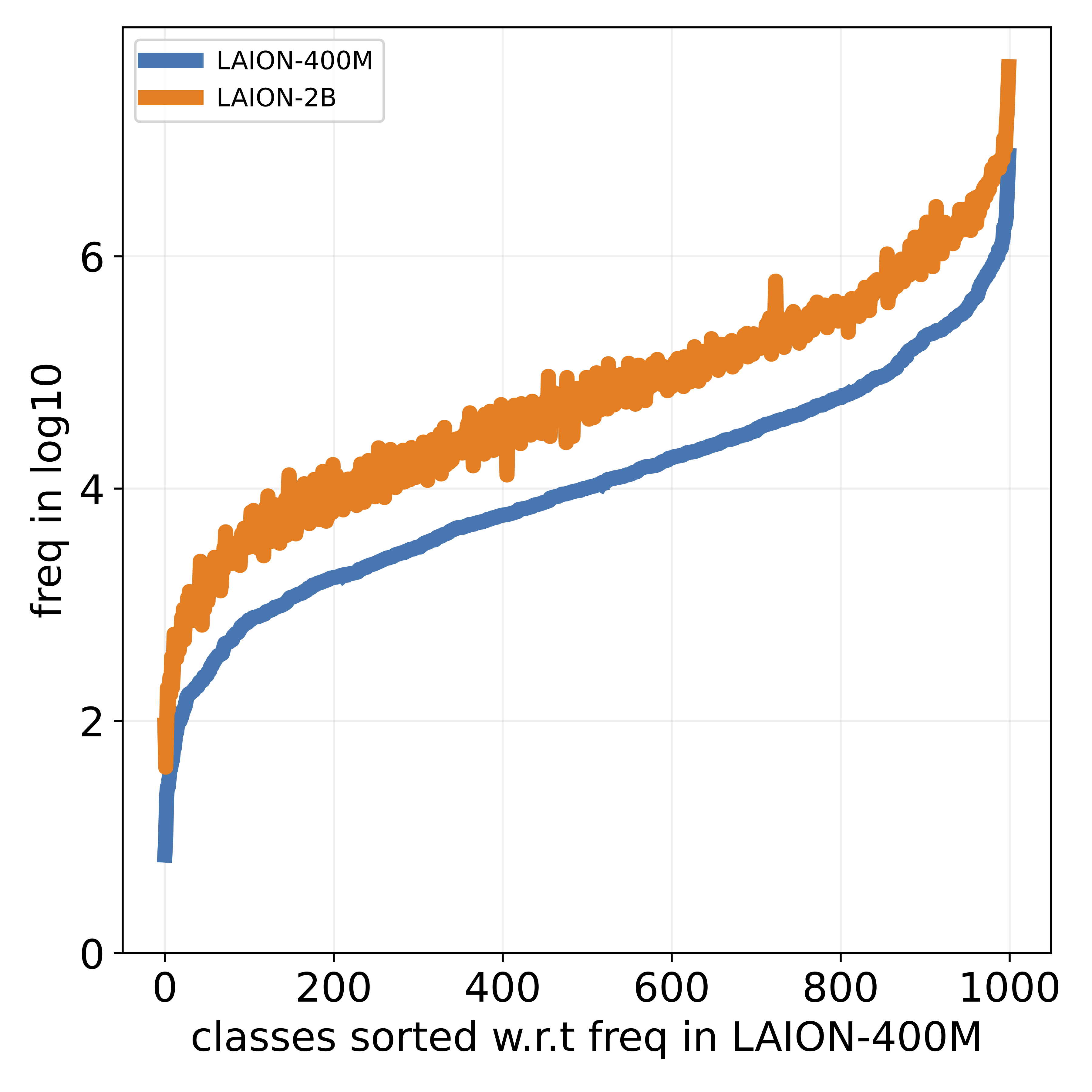
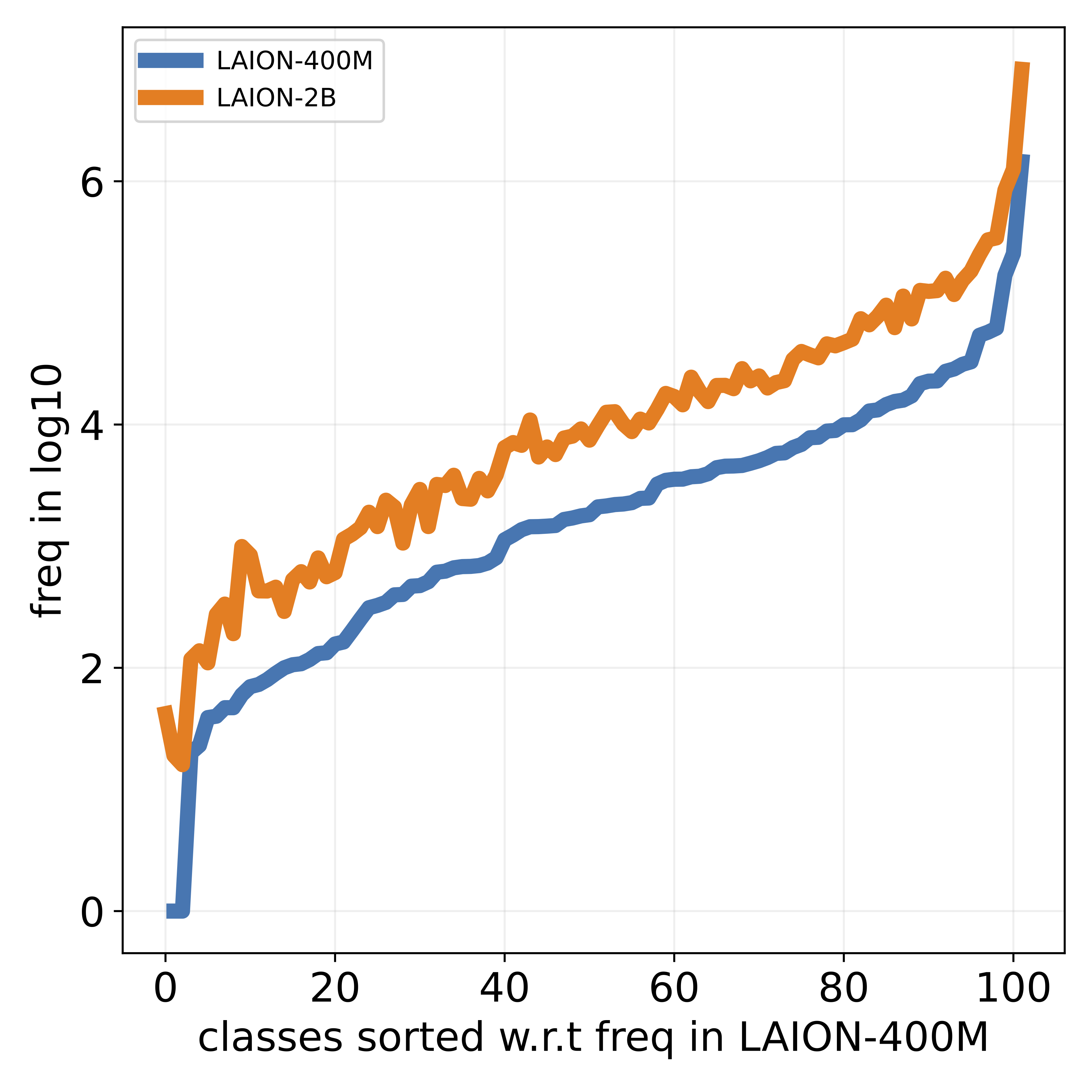
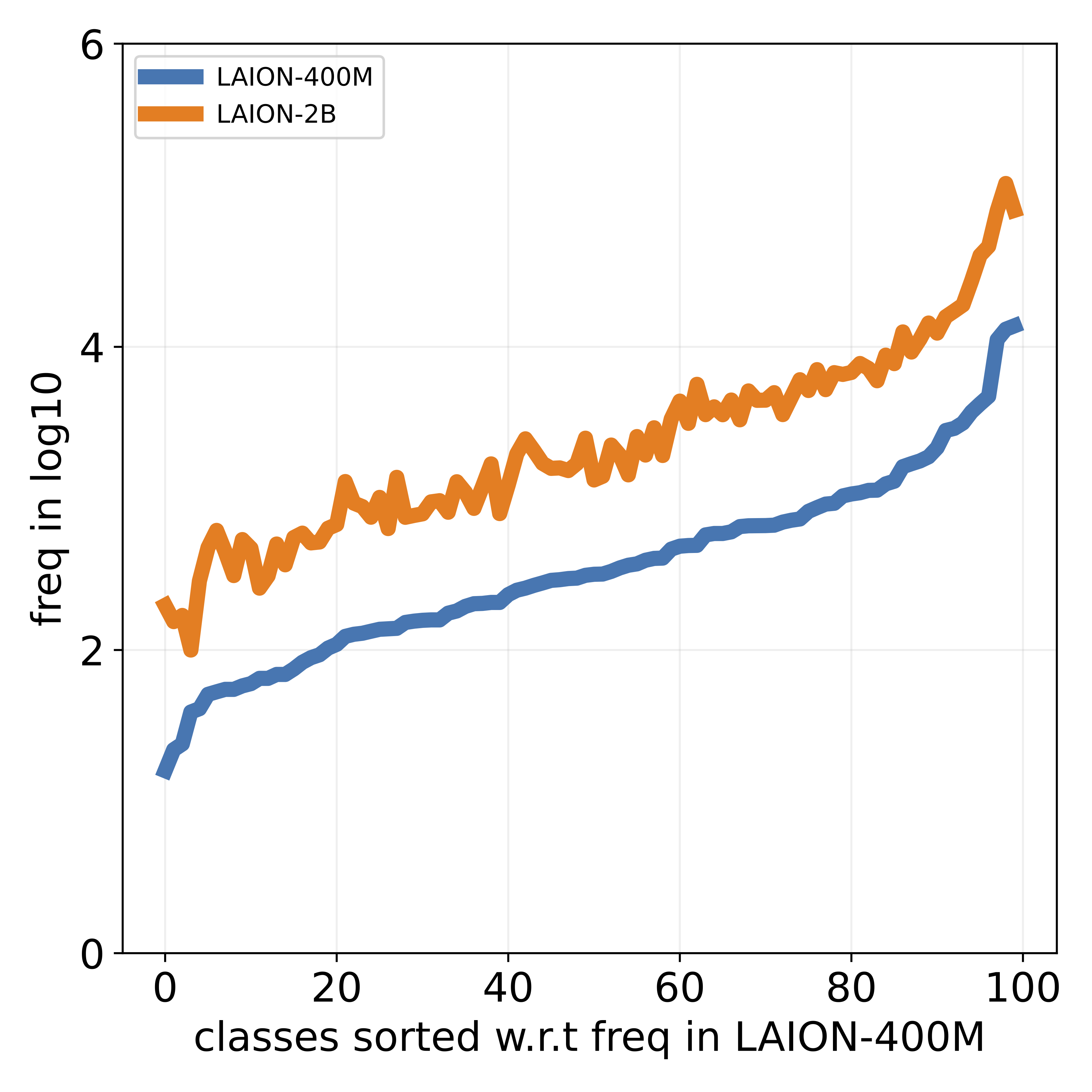
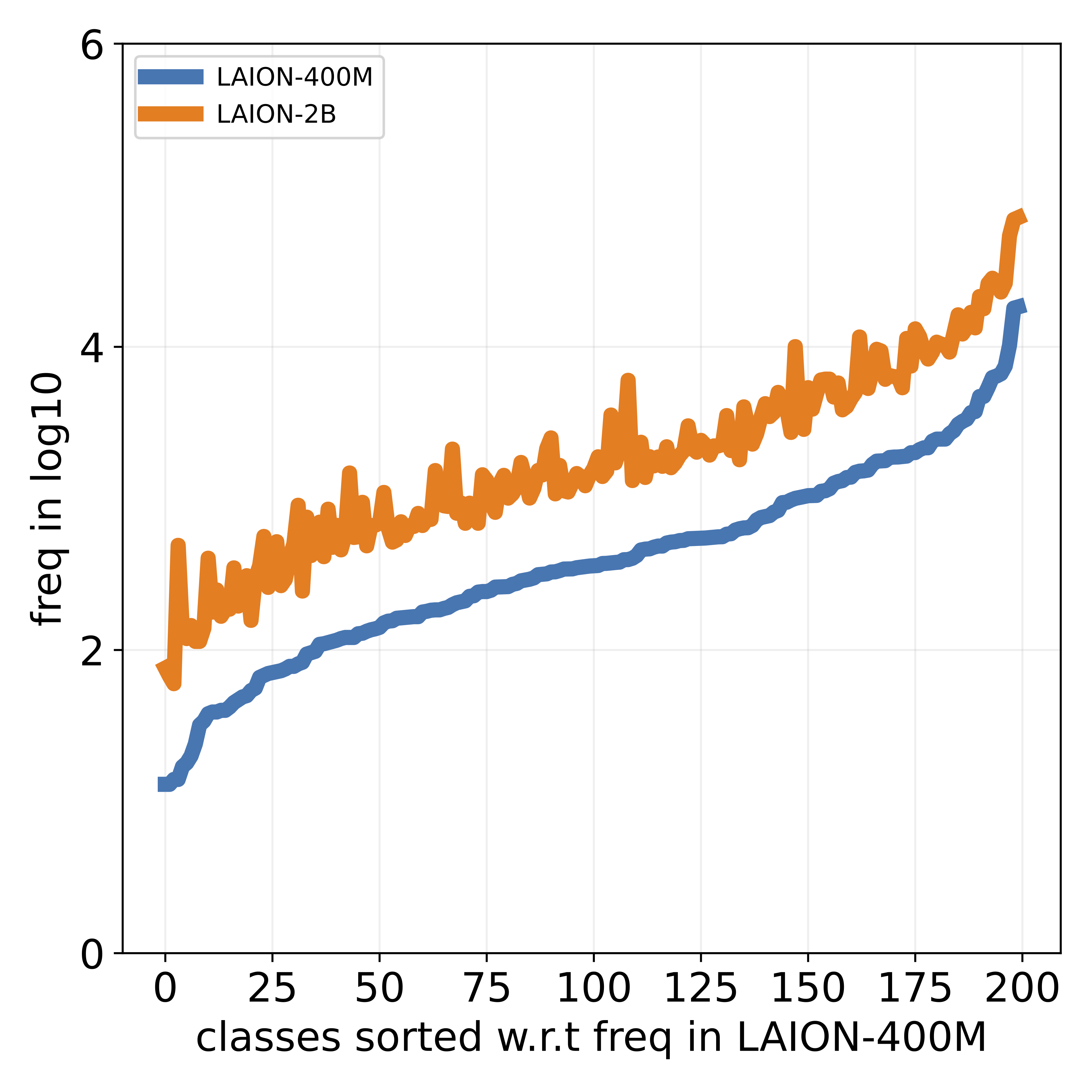
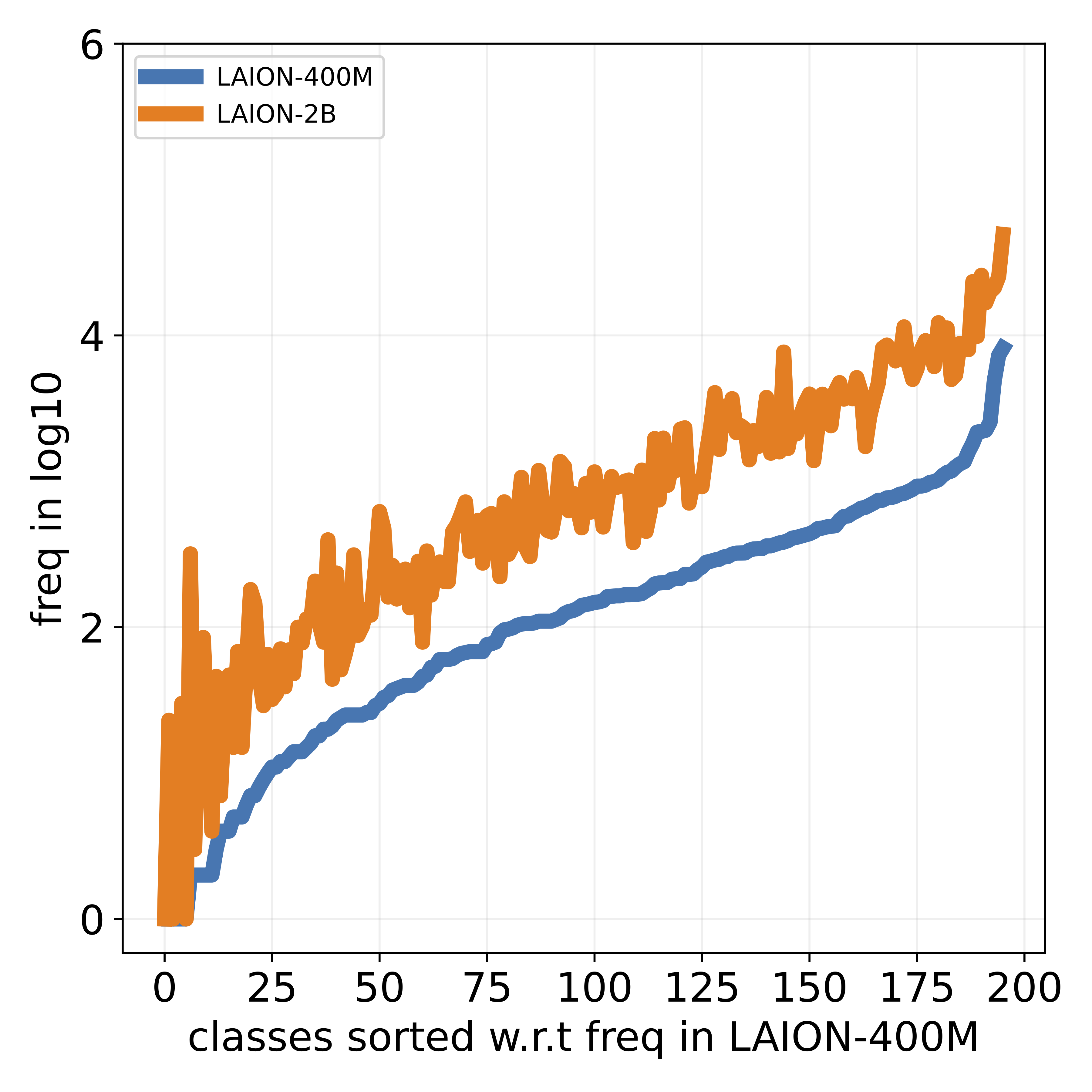
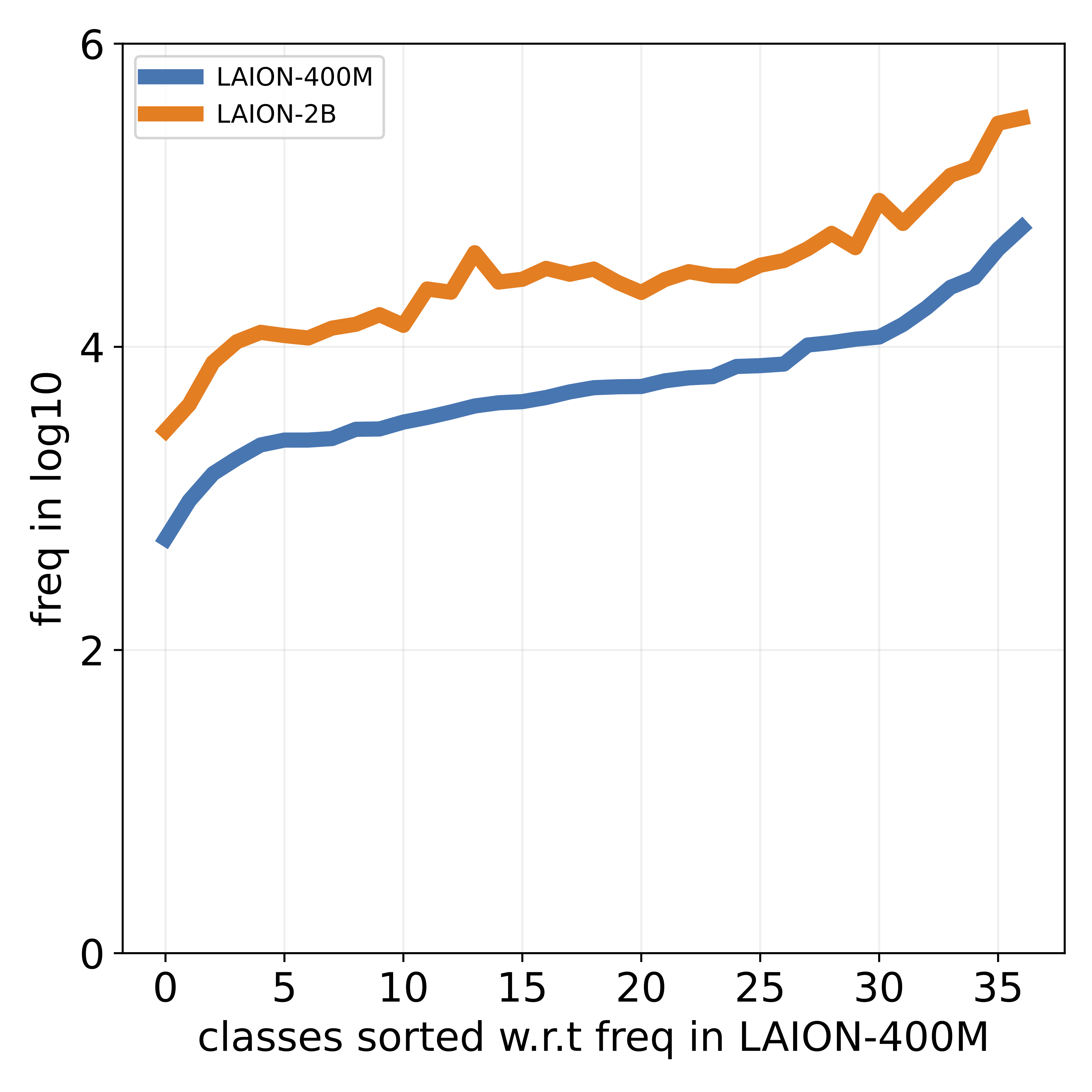
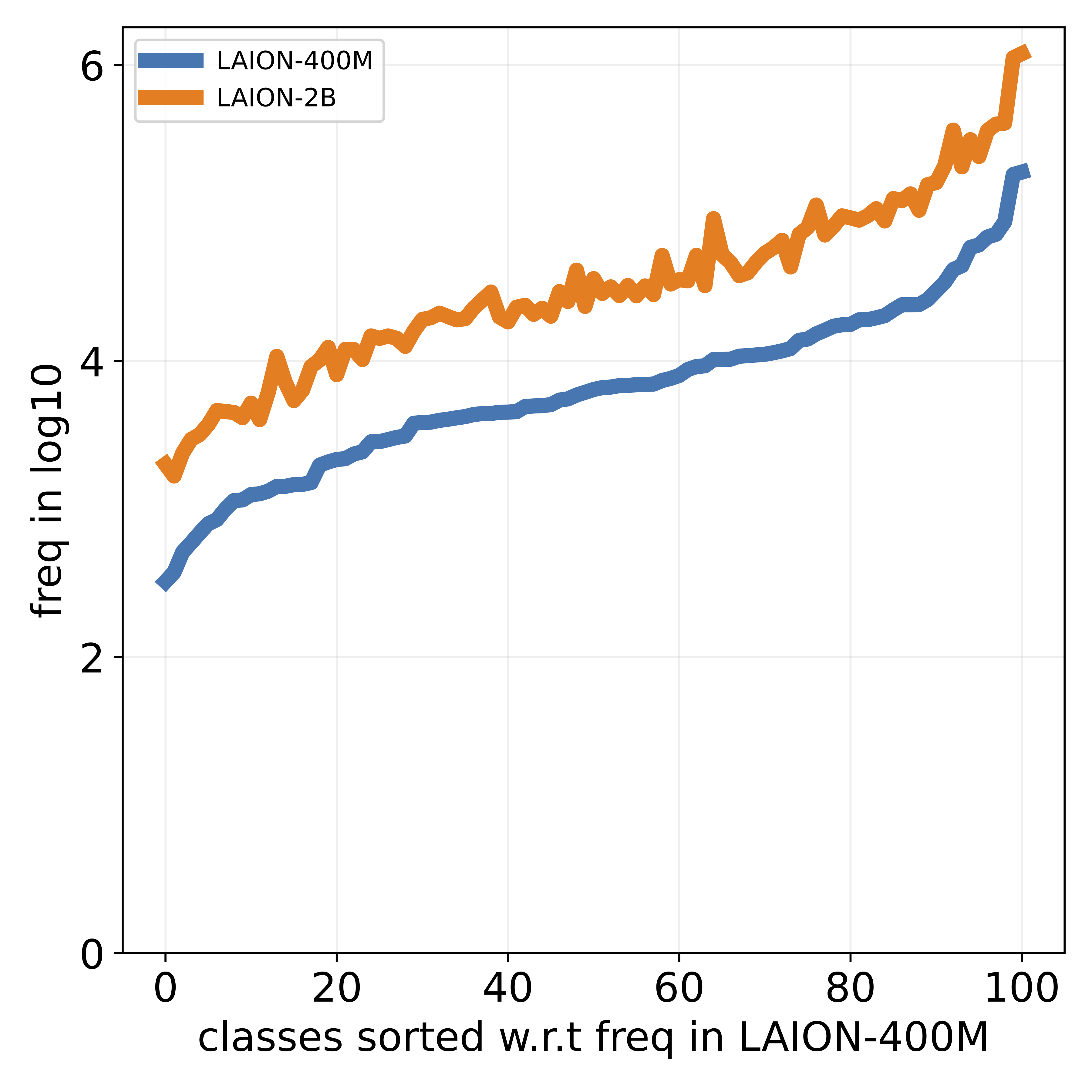
that popular datasets, such as LAION, exhibit a long-tailed
concept distribution, yielding biased performance in VLMs.
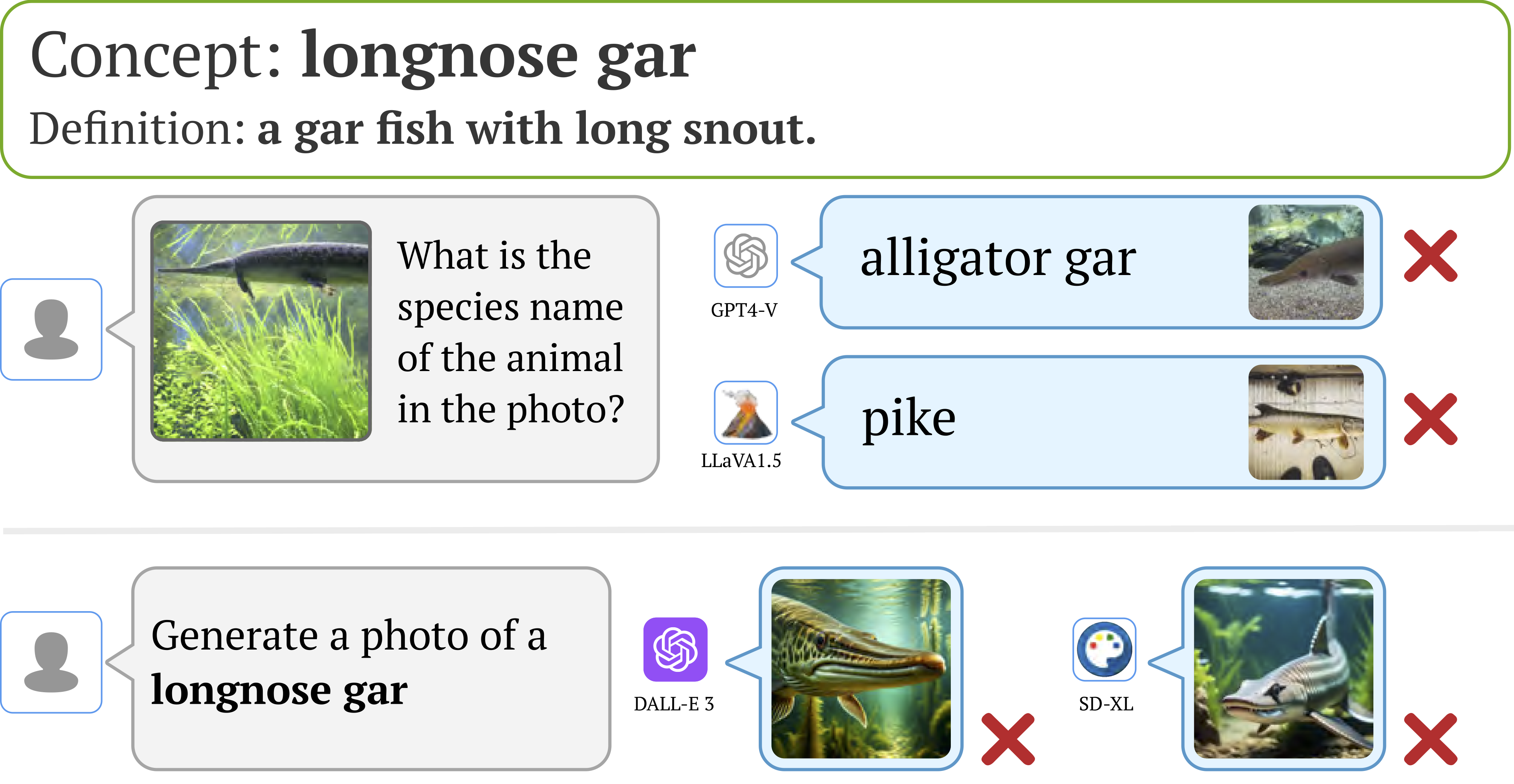
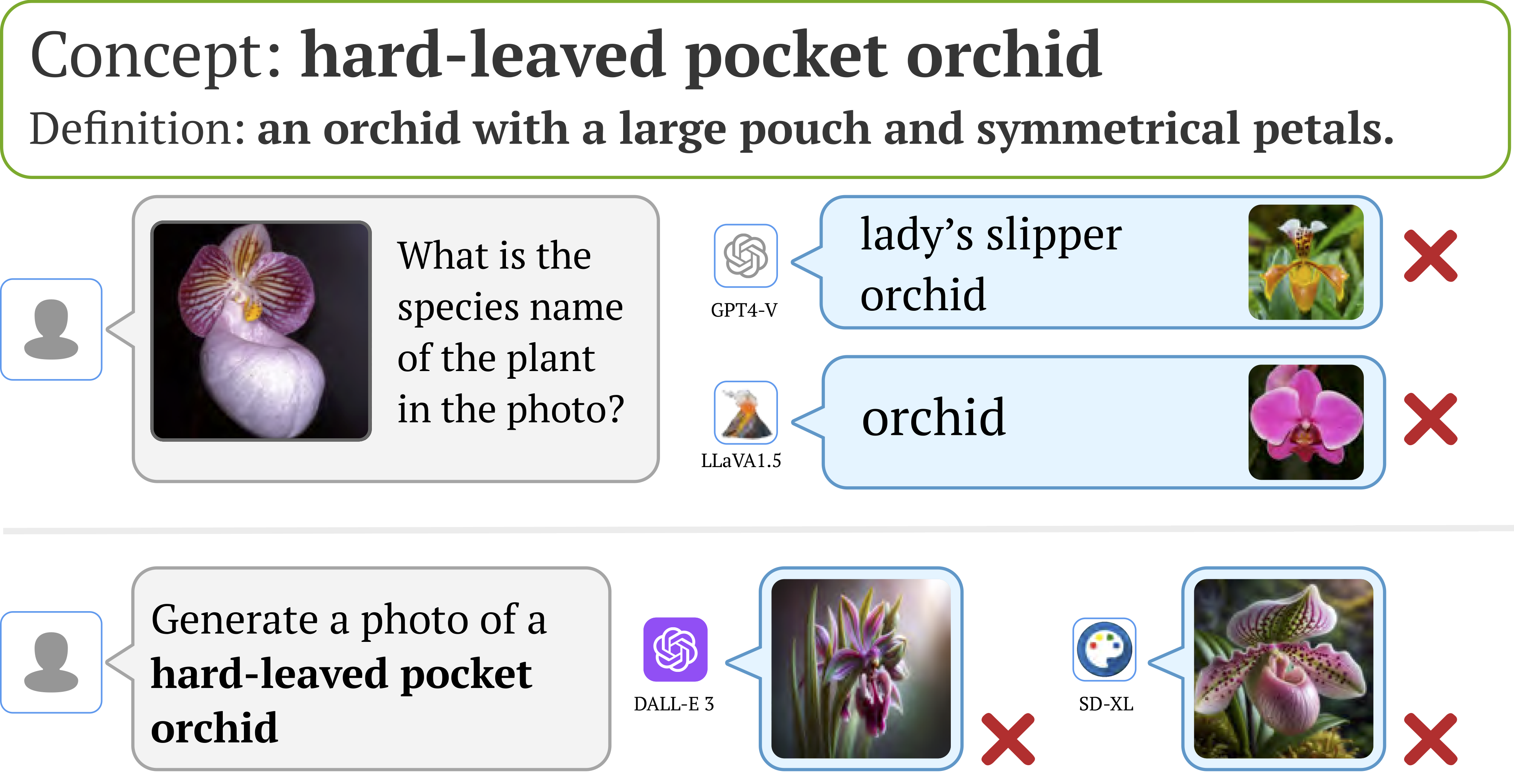
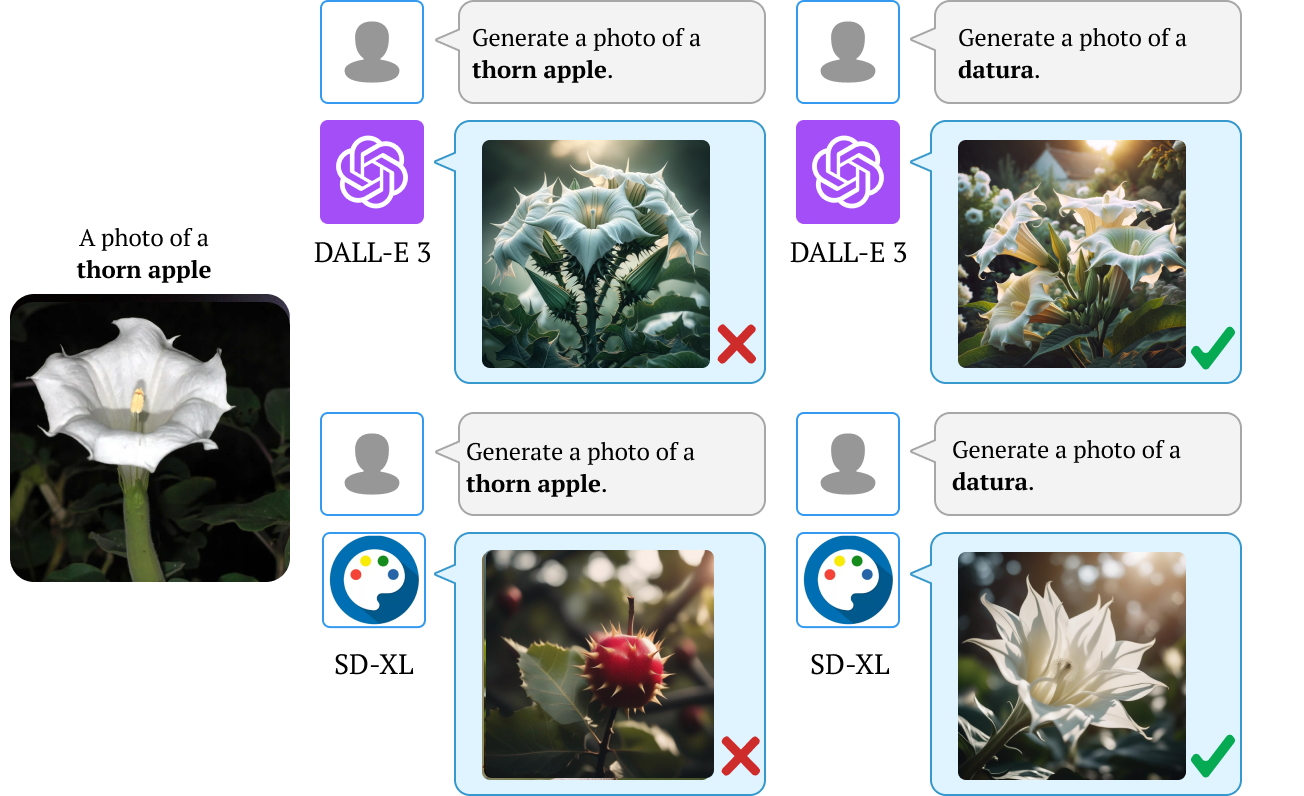
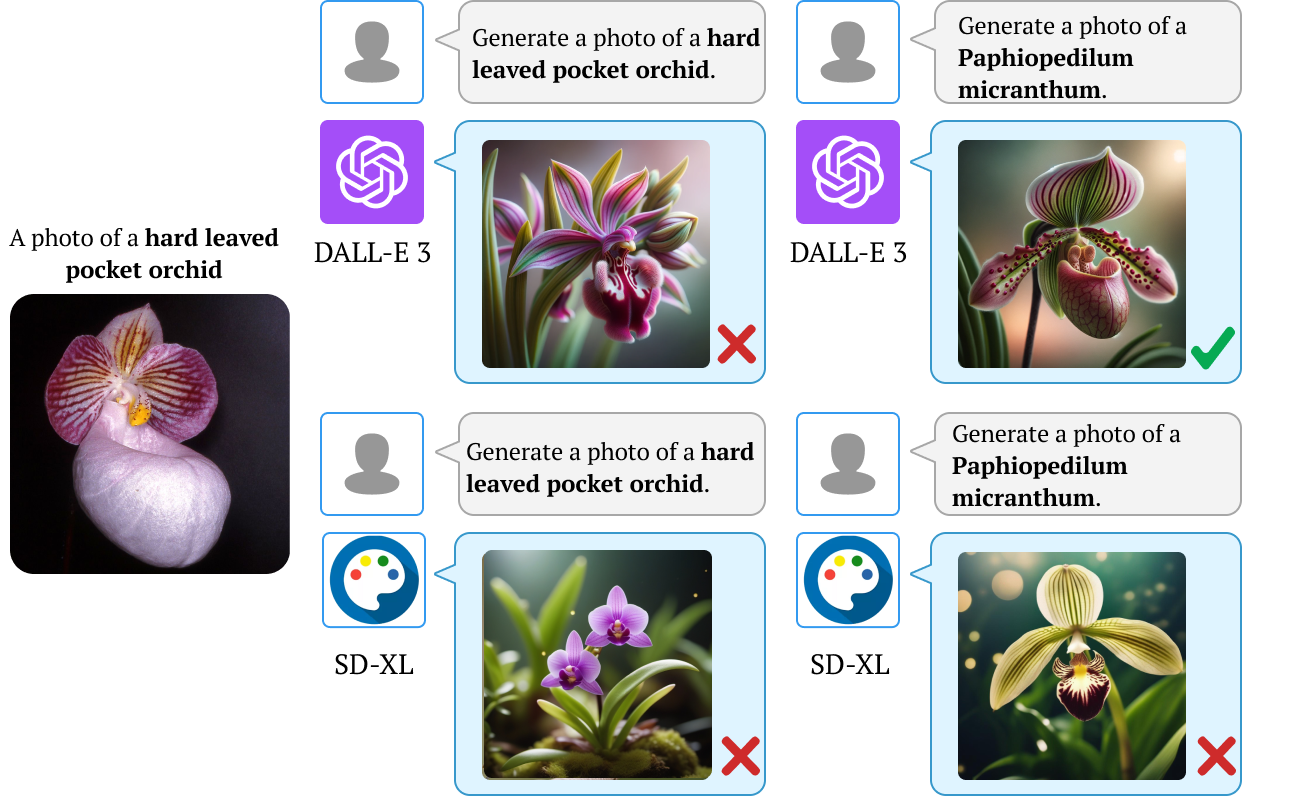
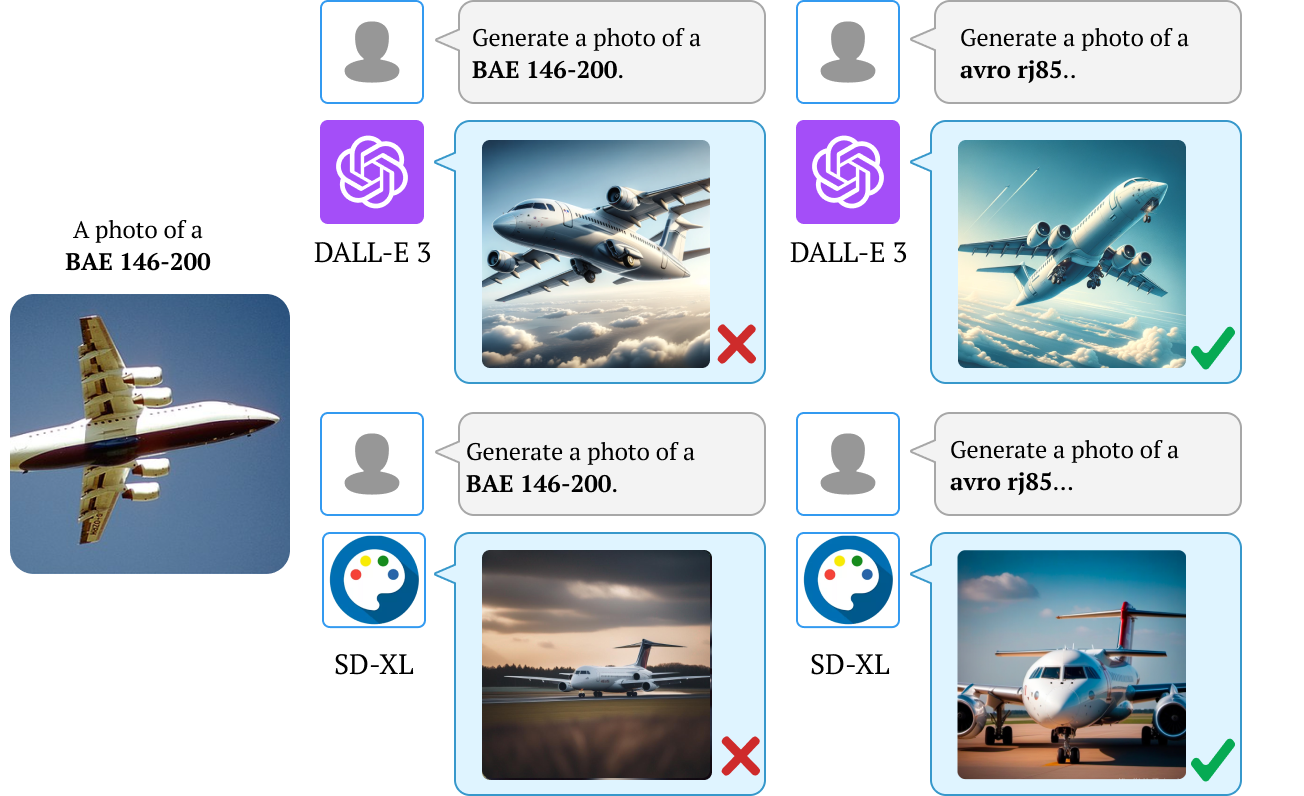
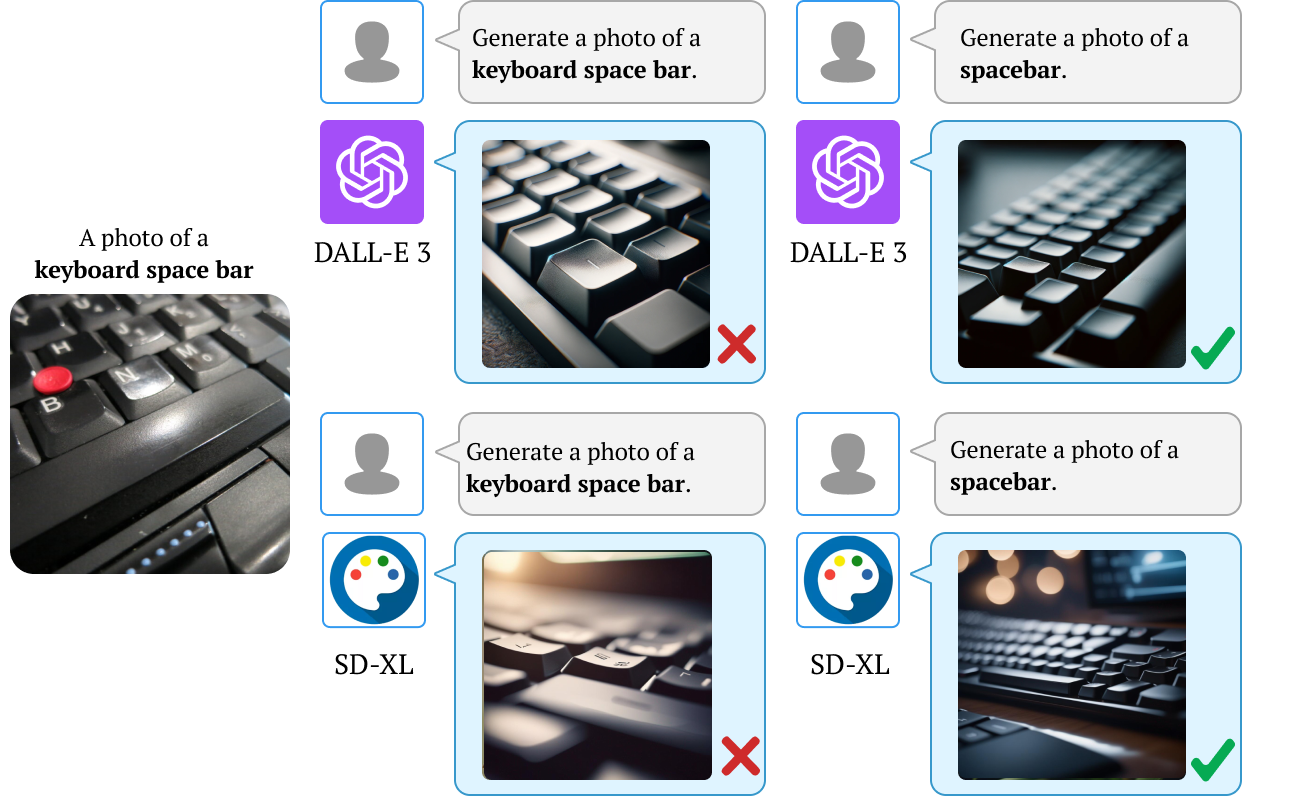
We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models
(e.g., Stable Diffusion), often fail to recognize or generate
images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we
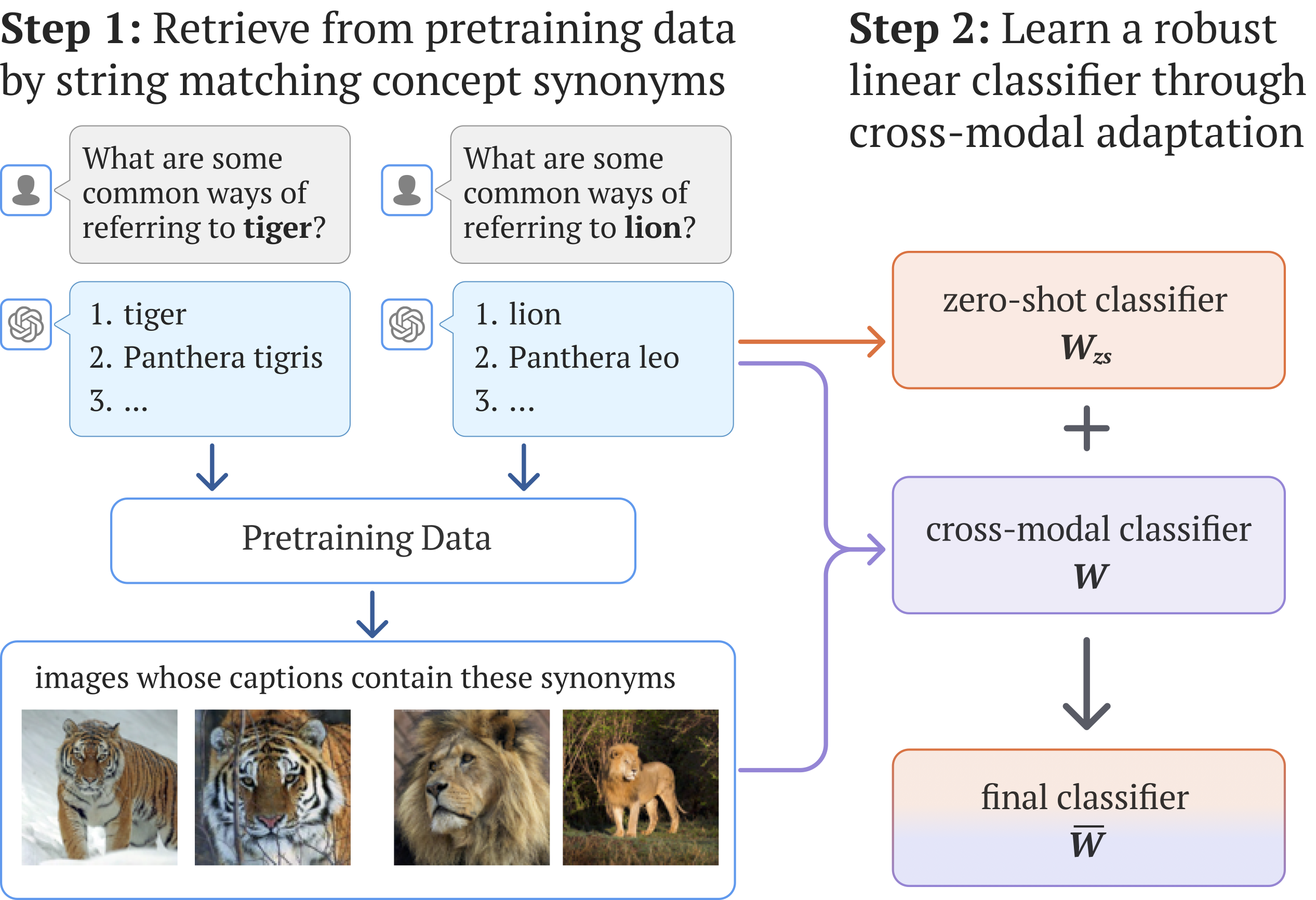
propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names,
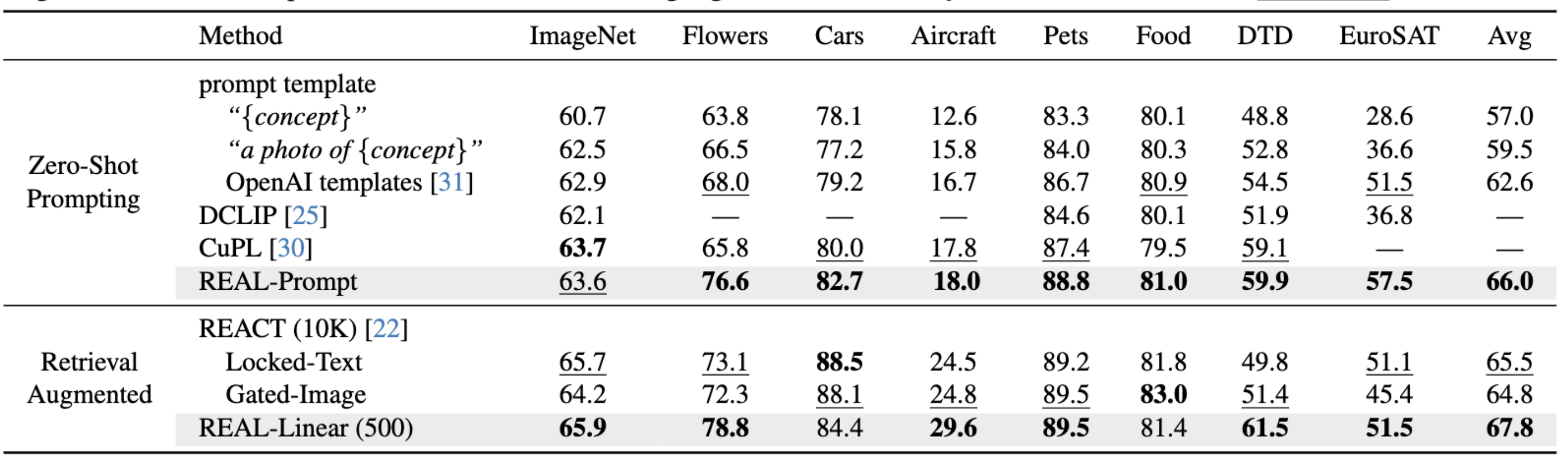
REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly
human-engineered and LLM-enriched prompts over nine
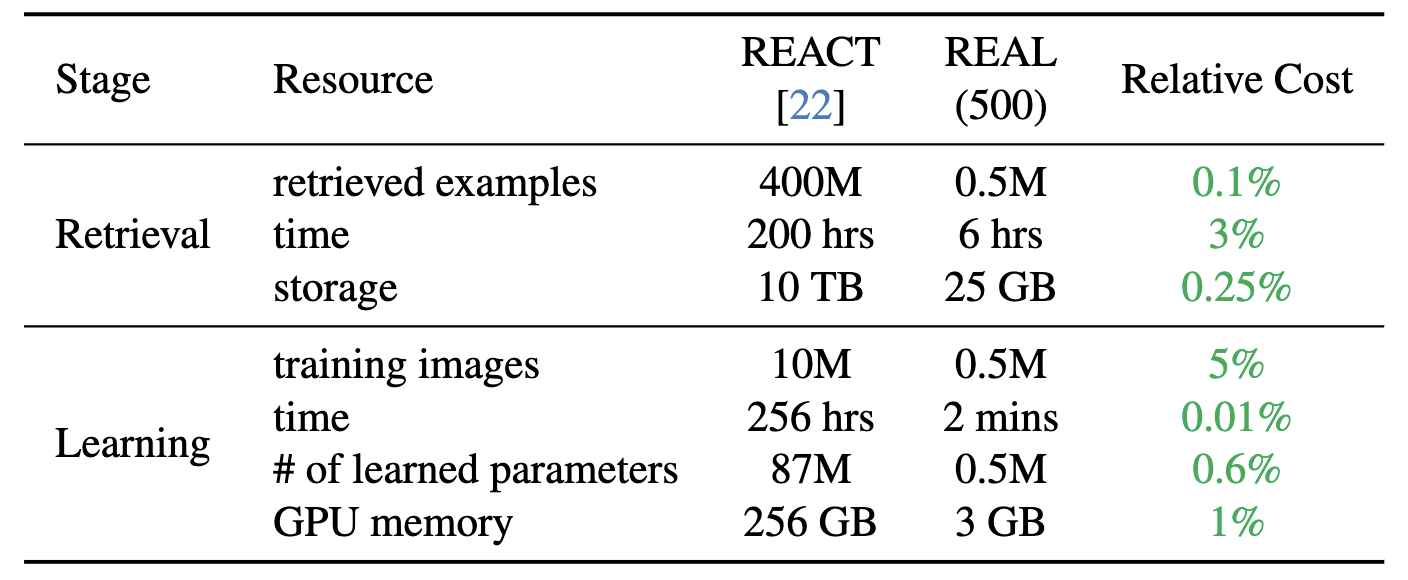
benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400× less storage and 10,000×
less training time!